Autoencoders are a type of neural network which work by learning abstract representations of data. Convolutional autoencoders are a type of autoencoder which use convolutional layers to encode and decode images. They are used to denoise, compress, and generate images. This article assumes knowledge of neural networks and convolutional neural networks.
Autoencoders are a type of neural network which are used to learn an abstract representation of data. They are able to compress data into a small number of abstract variables which describe the input data as accurately as possible, while providing significant dimensionality reduction. Therefore, they can be used for both compression and upscaling.
Standard feed-forward neural networks are only able to differentiate between distinct classes of data (e.g. cat vs dog), and cannot distinguish between a class and all other classes (e.g. is this a dog?). Autoencoders, on the other hand, are able to solve a one-class classification problem, such as detecting faces. This is because the autoencoder is trained to reconstruct the input data from a compressed representation of the data, so it learns the abstract features of the training data. This means that it can be used to detect new data which is similar to the training data, based on how accurate its reconstruction is.
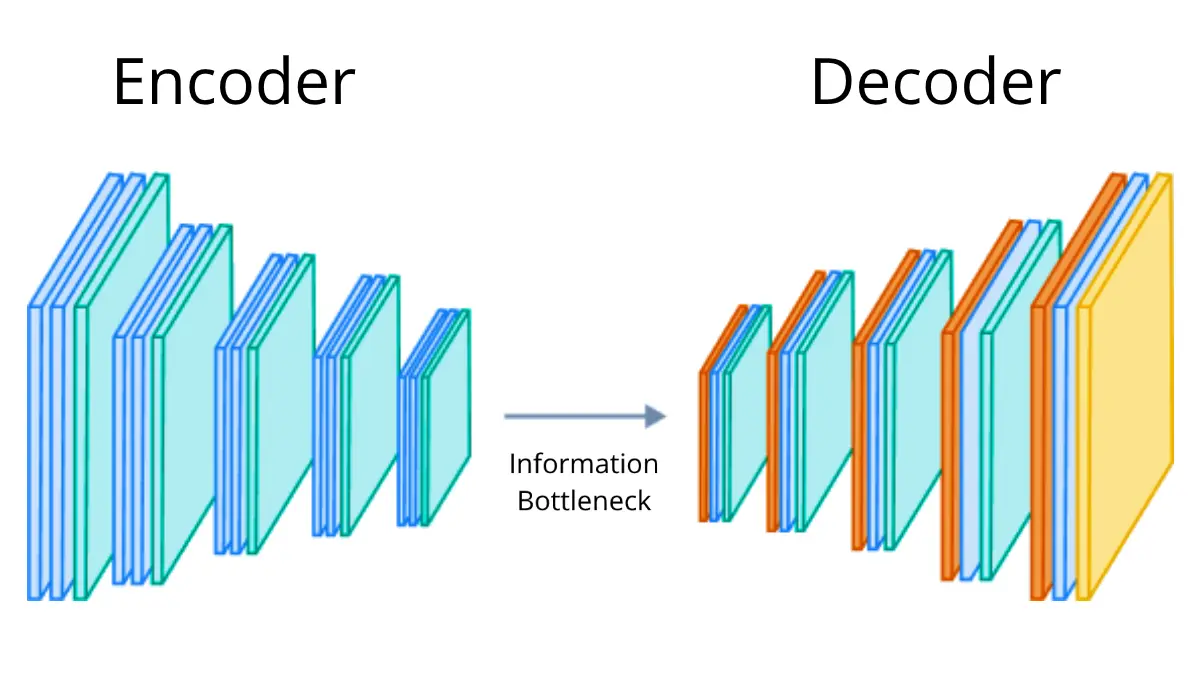
Autoencoder architecture
An autoencoder is formed of an encoder and a decoder. The encoder compresses the input data into a smaller representation, and the decoder reconstructs the input data from the compressed representation. When trained, the network learns to convert the input into latent variables. These variables try to accurately describe the input image to the decoder whilst using a fraction of the size. Once trained, the network will be able to accurately recreate images which are in the input domain. This means that if the reconstruction is close to the input image, the input image is likely to be in the domain of the training data.
The role of the encoder is to compress the input data into a smaller representation. The encoder typically consists of convolutional and pooling layers in a convolutional autoencoder, and fully connected layers in a standard autoencoder. The encoder is trained to learn the abstract features of the input data by converting the input into a latent representation.
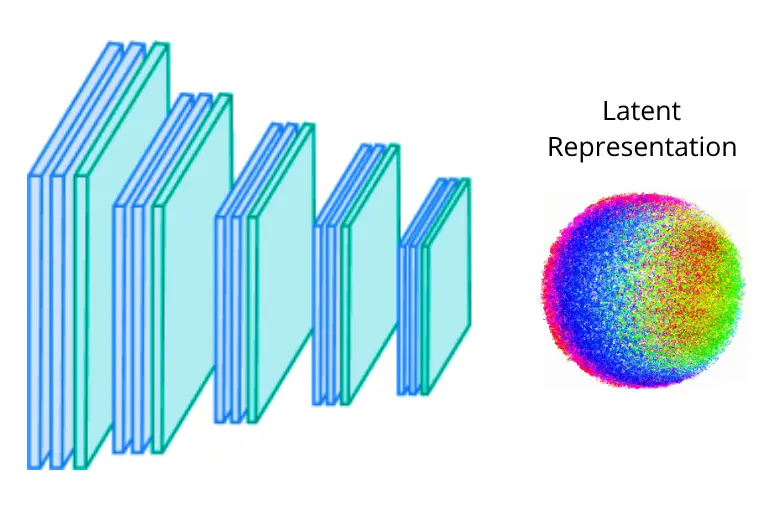
The latent representation contains abstract variables describing aspects of the input.
To describe the content of an image accurately, all individual pixel colours are not needed. Instead, certain quantitative parameters could be defined which are able to describe the image well.

The latent representation of this image could be: {dog: 0.98, terrier: 0.95, outdoors: 0.9, grass: 0.8, grey: 0.6, tan: 0.5, ...}
In practice, the latent variables are not explicitly defined, but are instead learned by the network. The variables will not be able to be interpreted by humans, but they will be able to be used to reconstruct the input image by the decoder.
In a convolutional autoencoder, which is commonly used with image data, the encoder is formed of a series of alternating convolutional layers and pooling layers, followed by a fully connected layer. The convolutional layers are used to extract features from the input image, and the pooling layers are used to reduce the size of the image. The fully connected layer is used to convert the image into a vector, which is the latent representation.
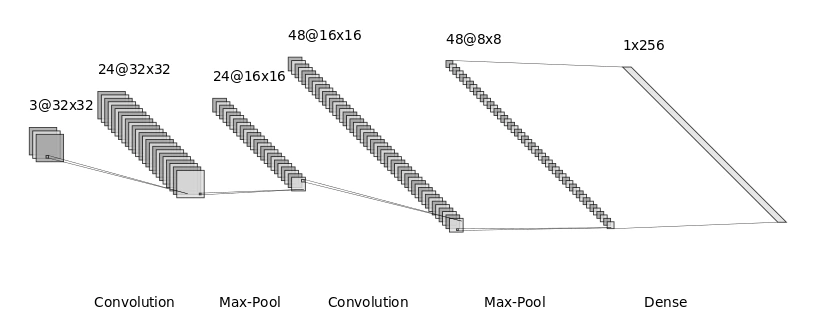
A typical encoder architecture for 32x32 RGB images.
The role of the decoder is to reconstruct the input data from the compressed representation. The decoder typically consists of fully connected layers in a standard autoencoder, and convolutional and upsampling layers in a convolutional autoencoder. The decoder is trained to reconstruct the input data from the latent representation.
In a convolutional autoencoder, the decoder is formed of a fully connected layer, followed by a series of alternating upsampling layers and convolutional layers. To enlarge the image, the upsampling layers are used to reverse the pooling layers, and the convolutional layers reverse the process of the convolutional layers in the encoder by using zero padding. For this reason, these layers are sometimes called deconvolutional or transposed convolutional layers.

Visualisation of a transposed convolutional layer. Credit for the graphic goes to Vincent Dumoulin, Francesco Visin
The upsampling layers typically use nearest neighbour to enlarge the image due to its simplicity.
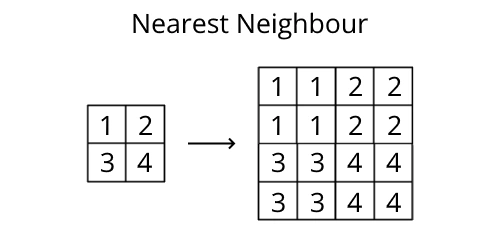
Example of upsampling using nearest neighbour.
Typically, the decoder is the reverse architecture of the encoder, which allows it to scale the latent representation back up to the original size of the input image. For each training example, the target output is the input image. The loss function is typically the mean squared error between the target output and the output of the decoder.
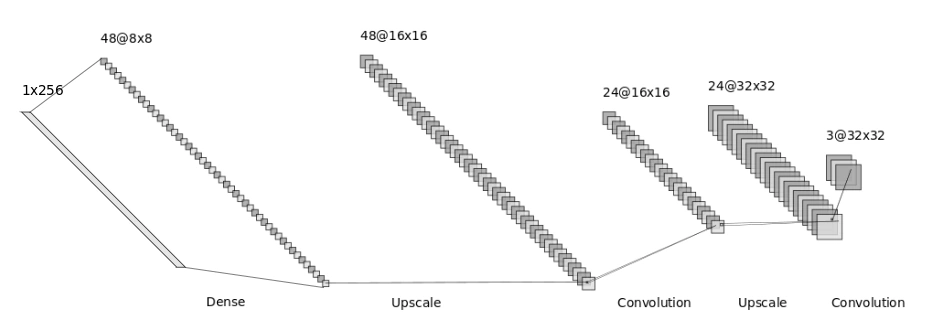
A typical decoder architecture for 32x32 RGB images.
The error of the decoder is backpropagated through the encoder. This causes the encoder to learn which features are important for reconstructing the input image, and slowly improves the quality of the reconstructed image.
To classify the input data, the accuracy of the reconstruction is evaluated. As the model has only learned to reconstruct data in the domain of the training data, an accurate reconstruction suggests that the input data is also in the domain of the training data. To compare the reconstruction and the input, a simple mean squared error (MSE) can be used on the RGB values of each pixel.

Out of training domain data leads to a much lower reconstruction accuracy.
As the model is only able to successfully reconstruct data which is in the domain of the training data, a threshold can be imposed to classify the input image.
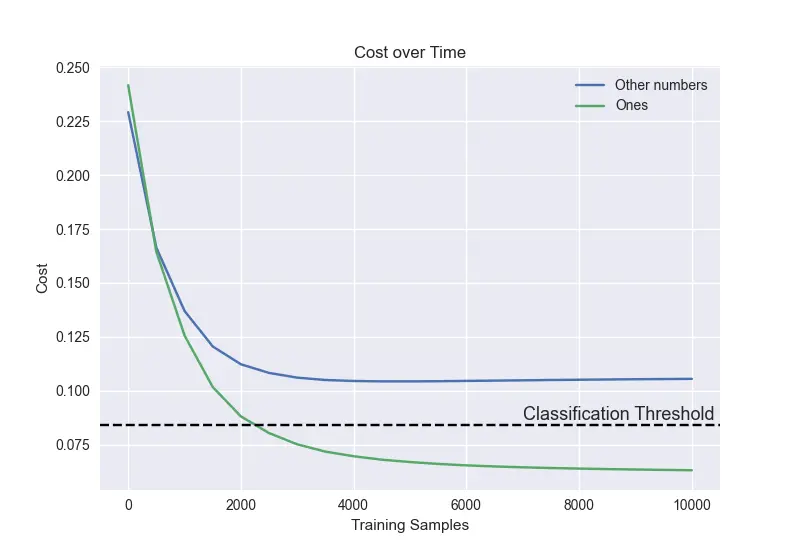
The cost of positive and negative examples over time in training. This model was trained to identify images of the number one using the MNIST dataset. The threshold can be set accordingly.
Using this technique, autoencoders can solve one-class classification problems. Autoencoders are also used in data compression, where the network is trained to reduce the dimensions of the input data while retaining its key features, making them a vital tool in machine learning. Use the links below to find my implementation of autoencoders from scratch.